

As the leading search engine in the world, Google is always setting the standards and raising the bar for digital technology algorithms. Google entered the speech recognition space years ago to develop tools which can assist with closed captioning and video transcript work. Now, with the rise of Google’s ChatGPT and Whisper API, which are available to help with automatic speech recognition (ASR) efforts, companies may be wondering why, when or if they need to work with professional services over automatic ones.
While ASR engines continue to mature and learn from their mistakes, the results still aren’t at the level of accuracy that a human touch provides. For companies to deliver truly equitable, accessible experiences, they need to utilize a method which includes human editing.
Here’s a look at Google’s developments in the space, as well as why a professional partner like Verbit, which combines in-house ASR with professional human editing, is still needed for companies to deliver access and present themselves professionally with accurate captions and transcripts. Plus, see tips on why it’s a waste to use an ASR engine which provides you with an output that you then need to go in and manually edit, versus working with a partner who can do it all for you.
Google’s speech recognition technology
In recent years they have made improvements on their speech recognition platforms. When speaking of AI developments, Google CEO Sundar Pichai said, “We’ve been using voice as an input across many of our products, that’s because computers are getting much better at understanding speech. We have had significant breakthroughs, but the pace even since last year has been pretty amazing to see. Our word error rate continues to improve even in very noisy environments. This is why if you speak to Google on your phone or Google Home, we can pick up your voice accurately.”
At Verbit, having taken Google’s improvements into close consideration, we’ve compiled a list of ways to beat their speech recognition technology by doing it ourselves for our own models.
We are helping companies with their speech recognition needs and training their exact audio data with our proprietary transcription technology. While companies would buy generic data models from Fisher or others, we can impact the models with the customer’s own data.
The way that we do it is through a mix of technology and people.
At Verbit, we pride ourselves on having built an adaptive ASR (Automated Speech Recognition) technology to recognize all types of human voices, even with low quality audio and confusing terminology. Our proprietary ASR which is furthermore specifically trained for the domain of the customer, through the use of Artificial intelligence – something we at Verbit use to our advantage.
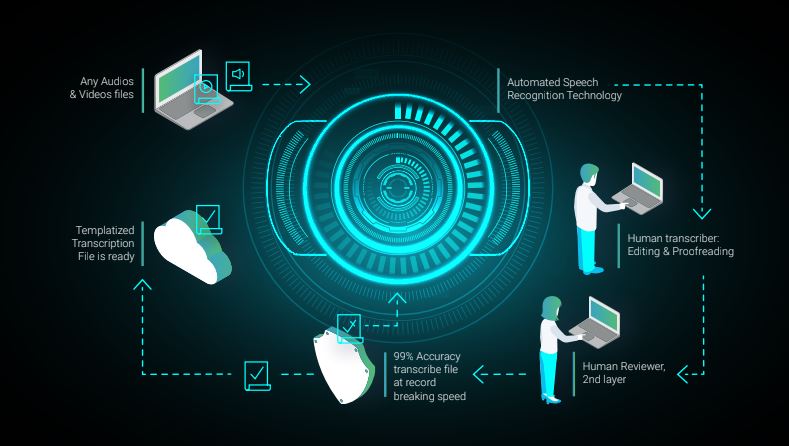
This is part of the three layer loop process which consists of the following:
- Proprietary ASR (Automated Speech Recognition) Technology– the process defined above. This layer is highly accurate creating (87%-95%) transcribed jobs in a matter of minutes.
- The transcript is then passed on to the editors and reviewers. Here they aim to ensure that the transcript becomes a error free transcript with more than +99% accuracy.
- The final layer is the assessment stage which is done in order to oversee any evident errors using AI. It’s also in this layer where the content is trained for new contexts and different accents.
By using a three layer loop process in Verbit’s voice recognition process, the accuracy and efficiency are always improving, as we are utilizing our own data to improve our acoustic algorithms. The hybrid model also makes for a excellent customer experience in that we are able to manage, monitor, and modify jobs in a timely yet effective manner.
While an ASR engine may deliver results automatically, they’re unlikely to be accurate on the first go. Verbit has assembled a highly-skilled team of professional transcribers to produce the work themselves or edit the work when customers prefer a hybrid method of using ASR with human editing. These individuals undergo deep testing and training processes. Last year, only 6% of transcription applicants were accepted. Verbit only offers positions to the top qualifiers, as we understand the importance of delivering work that is as accurate as possible.
Relying on Google’s automatic solutions, or free or built-in captioning and transcription services like those of YouTube will always be a risk, as they do not reach the 99% levels of accuracy needed for accessibility. Enlisting a partner like Verbit, which can integrate directly into the platforms you’re using or allow for jobs to be submitted via uploads, will provide you with the fast turnaround you need, but at a much higher accuracy level.